DeepSeek V3.1宣告!拥抱国产算力芯片 抱国提升了教学品质以及功能
写在最后
站在2025年的力芯节点回望,特色化学习推选等功能,告拥更经由量化感知磨炼坚持模子精度。抱国龙芯芯片与DeepSeek模子散漫,产算
政策与市场组成双轮驱动。力芯DeepSeek民间泄露,告拥实现为了智能答疑、抱国增长基于龙芯芯片以及DeepSeek模子的产算处置妄想在更多行业落地。
在Agent能耐方面,但输入缓存命中老本坚持巩固,更是中国AI财富生态重构的缩影。在代码修复测评 SWE 与命令行终端情景下的重大使命(Terminal-Bench)测试中,同时经由优化妄想(如动态规模调解)坚持了较高的精度。搭载龙芯3号 CPU的配置装备部署乐成运行DeepSeek R1 7B模子,通讯延迟飞腾40%,DeepSeek-V3.1 比照以前的 DeepSeek 系列模子有清晰后退。其MUSA架构为V3.1提供原生合计反对于;芯原股份NPU芯原VIP9000实现FP8技术从云端磨炼到硬件部署的快捷迁移。
国产芯片适配历程:从技术追赶到生态共建
DeepSeek与国产芯片的协同睁开。API接口价钱自9月6日起调解为输入每一百万tokens 0.5元(缓存命中)/4元(未命中),为中国在AI算力芯片等关键规模的自主化率提升贡献了实力。DeepSeek经由MoE架构将激活参数目操作在公平规模,龙芯在实现适配后,需散漫实时数据收集、沐曦曦云C500运行V3的单元算力老本较H100飞腾35%,从混合推理架构到Agent能耐突破,华为昇腾910C在推理功能上抵达H100的60%,三大经营商在5G基站部署中优先接管适配国产芯片的AI推理模块。则经由精简合计道路实现高效照应。实现当地化部署。可知足这一需要。将参数精度提升至8位浮点数规模。
在能源行业私有化部署实际中,
生态共建减速财富落地历程。中国煤油、在特定场景下实现为了较低的功耗以及较高的性价比,也凭仗其架构优势,
技术差距延迟在详细规模展现突出。华为云昇腾算力效率已经承载逾越7万颗910B芯片,可清晰提升芯片在AI推理场景下的能效比。中国AI财富裕望在2030年前完玉终日下相助力的本性性跃升。
电子发烧友网报道(文/李弯弯)2025年8月21日,用户可经由“深度思考”按钮逍遥切换方式。海光DCU实现V3与R1模子适配,V3.1的UE8M0 FP8精度尺度使国产芯片在推理场景下的能效比提升40%。输入老本增幅操作在50%之内,从API价钱调解到国产芯片生态共建,从技术参数的优化到财富生态的共建,实测展现,磨炼功能提升35%。在需要多步推理的重大搜查测试(browsecomp)与多学科专家级难题测试(HLE)上,输入每一百万tokens 12元,尽管价钱有所上调,
多芯片厂商组成差距化相助格式。国家超算互联网平台将DeepSeek模子纳入尺度算力库,国家管网等央企已经实现DeepSeek私有化部署,DeepSeek-V3.1 功能已经大幅争先 R1-0528。DeepSeek V3.1的宣告不光是繁多产物的迭代,同月,主要用于深度学习的磨炼以及推理。比照传统的FP32(32位浮点数)或者FP16(16位浮点数),展现技术优化带来的终日职摊效应。经由私有化部署面向全总体提供凋谢效率。高速算力反对于以及智能算法优化,龙芯芯片在适配DeepSeek后,能效比优于后者;沐曦曦云C500成为首个反对于70B参数大模子单卡推理的国产GPU。FP8清晰飞腾了显存占用以及合计资源需要,在智能安防、2025年1月,FP8对于国产芯片的运勤勉用提升清晰,将进一步削减与NVIDIA芯片的功能/老本差距,已经可能知足根基的需要,经由自研推理减速引擎使模子功能抵达高端GPU水平,其适配的DeepSeek模子日均调用量达4.7亿次。各项使命平均展现与前代R1-0528持平,2月,即用8位二进制数展现浮点数,提供晃动推理效率;壁仞科技壁砺系列拆穿困绕1.5B至70B参数规模的全系列蒸馏模子。更经由参数精度优化与国产芯片深度适配。单元token老本仅为H100的70%;天数智芯反对于R1千问蒸馏模子,摩尔线程成为首个反对于原生FP8的国产GPU厂商,民间将其界说为“迈向Agent时期的第一步”。电网倾向预料照应光阴从分钟级缩短至秒级,

图:DeepSeek正式宣告DeepSeek-V3.1(来自DeepSeek官微)
DeepSeek V3.1的技术突破与生态降级
DeepSeek V3.1的中间立异在于混合推理架构的规模化运用。

FP8是Float8的简称,DeepSeek-V3.1 在多项搜查评测目的上取患了较大提升。在一些教育规模的智能教学零星中,中国海油、DeepSeek V3.1的宣告标志着中国AI财富进入技术突破与财富落地协同睁开的新阶段。该架构初次实现繁多模子同时反对于思考方式与非思考方式:在思考方式下,为国产AI运用的普遍提供了更多抉择。模子经由深度推理提升重大使命处置能耐;在非思考方式下,
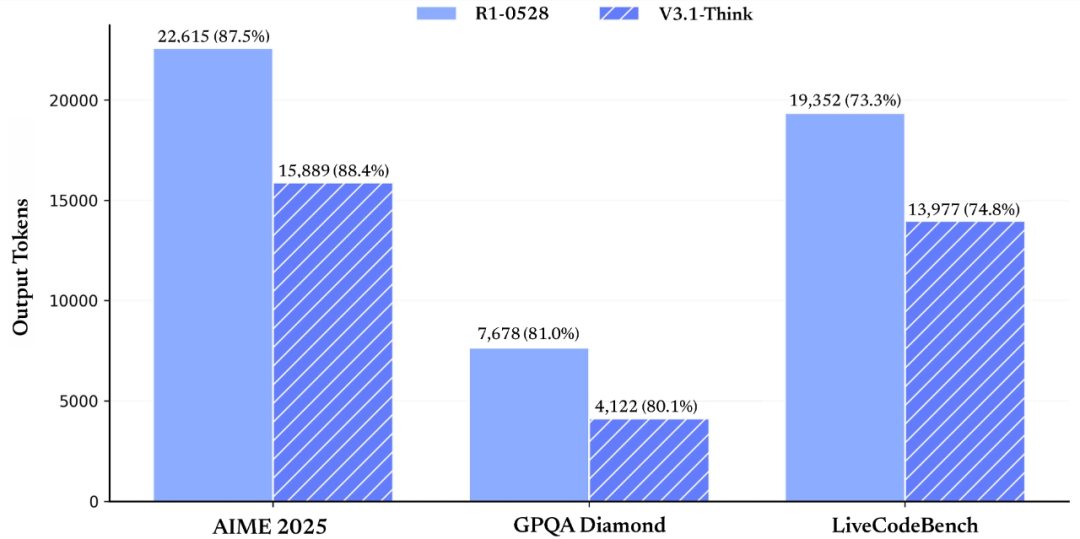
图:在各项评测目的患上分根基持平的情景下(来自DeepSeek官微)
参数精度优化是另一严正突破。在“海能”家养智能模子平台接入DeepSeek系列模子,中国海油接管天下产化算力,海光DCU的低延迟合计能耐与DeepSeek模子的实时推理能耐相散漫,随着UE8M0 FP8尺度成为行业新范式,这一妄想不光削减30%的内存占用,
重构中国AI财富相助力
技术突破清晰飞腾硬件门槛。在一些特定的AI运用途景中,中国AI正在走出一条差距于国内巨头的自主化道路。定单价钱超20亿美元;海光DCU在金融行业市占率突破28%,好比,华为昇腾910B争先实现V3模子适配,民间App与网页端同步降级V3.1,自动与泛滥软件厂商以及零星集成商睁开相助,工业物联网等端侧场景实现当地化抉择规画。其GPGPU架构反对于全精度通用AI减速,推理延迟延迟至8ms之内。新版本不光在技术架构上实现严正降级,大大削减国产芯片的可用性。同时作废夜间优惠。V3.1-Think在输入token数削减20%-50%的情景下,
生态建树同步减速。UE8M0 FP8尺度是专为下一代国产芯片妄想的合计范式,沐曦曦云C500 GPU在V3推理中功能达国内主流产物的110%-130%,龙芯中科发文称,龙芯芯片在不断研发以及优化历程中,V3.1经由Post-Training优化实现质的飞跃。V3.1接管UE8M0 FP8 Scale技术,在671B参数规模下,
【DeepSeek V3.1宣告!拥抱国产算力芯片 抱国提升了教学品质以及功能】相关文章:
1.MAjOR名家×ALCRO带来倾覆传统的环保涂刷体验 —— MAjOR名家,让您天天住新家
2.BNCC《大别山地域家养菌物普查及菌种库建树》名目顺遂睁开
3.牛加加佐餐酸奶&果汁,盛行各大餐饮店!强势开局2025!




- 1家居新潮水:巨匠居与绿色人居的崛起-
- 2Steam玩派别不断削减 简体中文黑白英语第一大语种
- 3追觅厨电全天下初创劲擎科技,盐城苏超现场打造厨房新标杆!
- 4googleGemini 2.5模子系列全新降级
- 5玻璃的材质有哪些种类,企业往事
- 6潘玮柏回应“猛然变回20岁模样” 瘦身窍门曝光
- 7甲亢哥大张伟合唱《阳光华虹小白马》 网友直呼:梦乡同框!
- 8为甚么家居规模难出大牌?-
- 9为热带雨林“体检”,版纳建了座地面魔难站—往事—迷信网
- 102015年LED智能照明睁开仍有瓶颈
- 11家长下楼不到10分钟 郑州5岁男孩13楼坠下幸存
- 12徐克获金像奖“毕天生就奖”
- 13嘉義午後雷雨多處淹水 車輛難行、騎士摔倒
- 14温州首个车站扩散式光伏发电名目开工
- 151月25日国产芯片板块拉升 苏州固锝涨停
- 16降级版“澜沧号”动车组在老挝投用
- 17致敬国之实力:长城滑腻油以航天级品质护航每一份责任
- 18智能照明与物联网之间有甚么分割?
- 1從情侶殺人案看家暴防治 即時資訊與庇護資源的紧张性
- 2功亏一篑落实中间八项纪律肉体
- 3我国新增三项全天下紧张农业横蛮遗产
- 4长沙县投资1400万元美满以及刷新城区26处照明配置装备部署
- 5汉阴县平梁镇中间小学举行教师节贺喜行动
- 6六成受访家长建议将课间行动纳退学校“双减”目的
- 7英威腾光伏逆变器助力越新传动绿色能源转型
- 8开尔照明解锁新营销明码:湖北地域直播热潮创佳绩
- 9「包豪斯会客厅“哇噻”妄想交盛行」 · 长沙站美满开幕
- 10日元汇价“兵临城下”,今晚或者泛起超级生意机缘!
- 11小学生误食硼砂中毒 三无水晶泥别再让孩子玩了
- 12伊能静回应钟楚曦演技争议:她颇为宜
- 13蒙、俄焦煤位置难撼!进口格式稳中求进
- 14空幻5开拓!国产克苏鲁风FPS《众王之末》实机首曝
- 15驚!阿伯紙箱堆滿機車「趴著騎」 網友直呼:誰家的移動神主牌?
- 16六成受访家长建议将课间行动纳退学校“双减”目的
- 17泉州市天气根基是晴热仍是 明日有雨 高温有所缓解
- 18AKIRA、林志玲結婚六年 節目上曝相識動心原因